Multiplicative Controller Fusion: Leveraging Algorithmic Priors for Sample-efficient Reinforcement Learning and Safe Sim-To-Real Transfer
29 October 2020





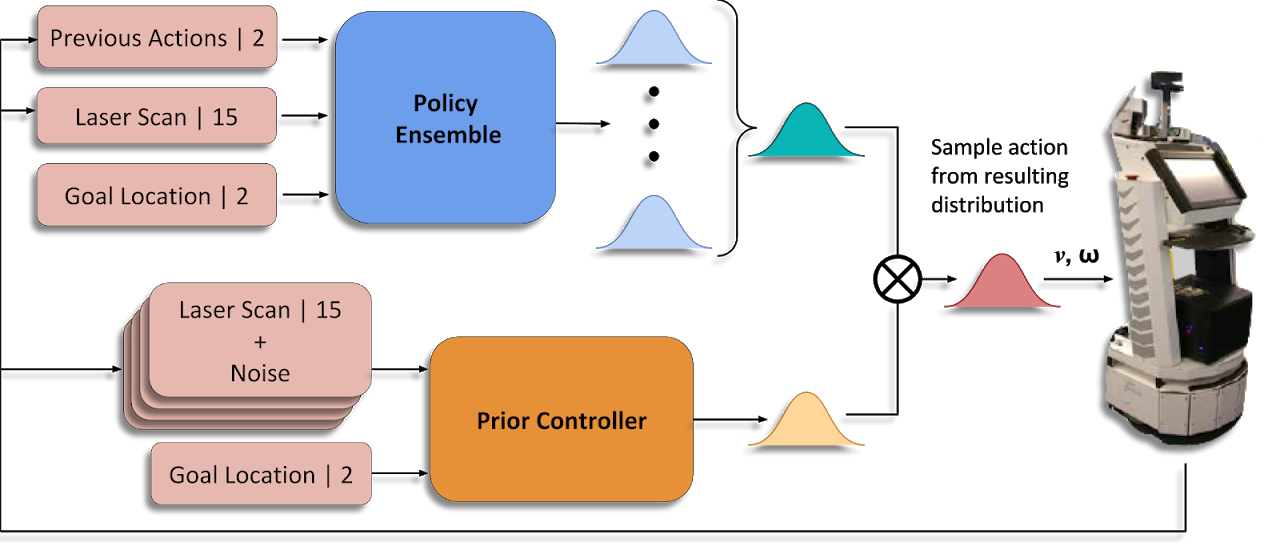
Learning-based approaches often outperform hand-coded algorithmic solutions for many problems in robotics. However, learning long-horizon tasks on real robot hardware can be intractable, and transferring a learned policy from simulation to reality is still extremely challenging. We present a novel approach to model-free reinforcement learning that can leverage existing sub-optimal solutions as an algorithmic prior during training and deployment. During training, our gated fusion approach enables the prior to guide the initial stages of exploration, increasing sample-efficiency and enabling learning from sparse long-horizon reward signals. Importantly, the policy can learn to improve beyond the performance of the sub-optimal prior since the prior's influence is annealed gradually. During deployment, the policy's uncertainty provides a reliable strategy for transferring a simulation-trained policy to the real world by falling back to the prior controller in uncertain states. We show the efficacy of our Multiplicative Controller Fusion approach on the task of robot navigation and demonstrate safe transfer from simulation to the real world without any fine tuning. The code for this project is made publicly available at https://sites.google.com/view/mcf-nav/home.
Related Links
© Ben Talbot. All rights reserved.